In this blog, Bob Charapata and Cory Cundy simplify Git’s workflow to help reduce its complexity for your team.
Our data consultants use Git in almost all of our projects. Even though Git can get quite complex, you don’t need to grasp all the complexities to find a lot of value in it. In this blog, we will simplify those complexities.
Overview of Git
At a high level, Git lets you effectively manage your code in a multi-developer environment. It lets you work on features and fixes with any number of development team members. Even if only one team member is on a project, this technology is valuable because it lets you effectively separate features and work on them in isolation. It can eliminate deployment dependencies.
However, Git’s biggest benefit is that it helps prepare for automated deployment and release processes – particularly with the branching/merging strategy. This allows your development teams to focus on development instead of managing deployments.
Terminology
Before we can dig into these advantages, let’s run through some basic Git vocabulary.
Checkout
Checkout in Git is a little different from working in a centralized version control system. It’s not checking out a single file. Instead, it creates a repository with all your files and checks them out in the state they were in at the time you worked on a feature.
Commit & Stage
Stage is used when you’re ready to commit. Commit is the equivalent of the check-in process for a centralized version control system. Rather than checking in an individual file, commit checks in the entire state of your code as it is right now. When you’re in the process of performing a commit, you could potentially stage files. Staging lets you pick the different files you want to commit. You could have four files being modified, but only three of the files are in the done state, and you may be working on a proof of concept for the fourth file. You can stage and commit just those three files that are ready.
Push
In Git you have a local and a remote repository. Push pushes the changes that have been committed in your local repository to the remote. The reason for performing a push is that if you have a multi-developer environment, then the other developers can see your changes using a fetch.
Fetch
Fetch updates the tracking information or metadata for all the branches in your local Git repository from the remote. A fetch doesn’t update all the files for each branch in your local repository, but all the information about all the branches.
Pull
A pull is a fetch and then a pull. It is an action that occurs on a specific branch, whereas a fetch is something that occurs on multiple branches. If you have multiple branches that are tracked in your remote repository, a fetch will get the latest version of all of them. A pull then fetches all of those branches, and then it updates your specific local branch with the latest changes.
Sync
A sync is a pull and then a push. It pulls the changes from the remote first, and then it pushes the latest changes.
Prune Remote Branches
When you set up an automatic prune, it will make sure that branches that are deleted in the remote will also be deleted in your repository. Again, this is particularly helpful when multiple developers are working together.
Rebase Local Branches
A rebase essentially resets local branches. This (and some other actions) could be used to reapply changes you’ve already done in a few of your commits.
Diff and Merge Tools
Diff and merge tools let you compare files before you commit changes.
How Repositories are Structured in GIT
In a centralized version control (like a TFS system), all the files are on a remote repository and you always work from that repository. You have to check out and check in the files from the remote repository. In contrast, Git has multiple repositories. How many? It’s always N+1: the number of developers you have plus the remote.
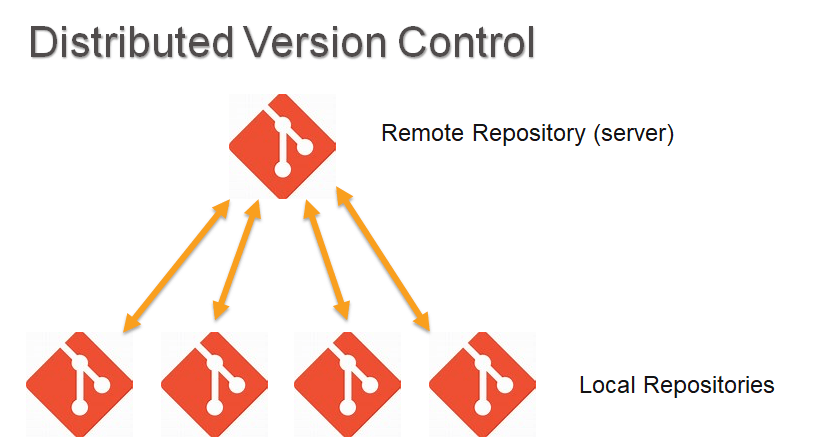
Each developer has their own repository on their computer. So how do they keep in sync with each other? If one makes a change, then he performs a push to the remote repository, and the other developers would perform a pull. The arrows in the image above are bi-directional because you pull to get the latest changes, and you push to update the latest changes you have performed to the remote repository. There’s never an arrow between each of the repositories that developers have because we use that centralized remote repository for the update.
What if I don’t see changes when someone pushes to remote?
Local repositories don’t automatically sync with the remote repository. To see changes that have occurred in the remote repository, perform a pull. Typically, you do that right when you’re about to start working on a feature branch – especially if you’re collaborating with another developer.
If you’re about to branch from main, perform a fetch. That will update your local repository with the changes that have been pushed to the remote since the last time a fetch was performed. That will keep your repositories up to date.
Branching Strategies and How to Work with Branches
Branching strategies can get complicated. In the simplest version, you have a main branch and feature branches. When we create our feature branches (and there can be any number of them), we branch off a main because that’s the last known good version of production, and then we perform development. When we’re done with that development, then we merge our changes back into main.
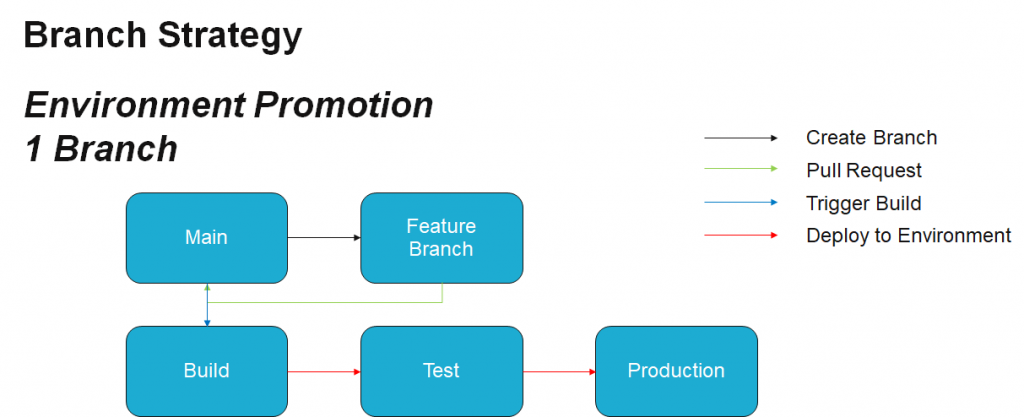
The reason for this branching and merging strategy is because it works toward continuous integration and continuous deployment strategies. That main branch can be monitored, and when changes occur to it, it kicks off a build which could then potentially automate the deployment to a test environment. With approvals, it could even deploy to production. Those are the actions that occur based off good branching strategies. Since this is simple, it’s usually what we suggest to customers who are new to Git.
Working with Main
In main, you don’t have to check out that branch at all. If you check it out and start performing actions on it, it can be easy to get confused. If you want to see how your code is structured in production, you could check main out to see. Otherwise, you want to leave main alone.
A common gotcha we see from people new to Git is that they have main checked out (maybe to view the code or because it’s the only branch, etc.) and then they forget they have main checked out and start making development changes right in the main vs a feature branch.
Additionally, sometimes organizations will lock down the main branch. Everything can look fine as you are making changes, but it might deny access when you push that code.
You also want to keep the main branch as close to production as possible. That includes keeping it clean of features that are being actively developed, are in flight, or are not tested. When you’re done with your feature development and are ready to deploy, that’s when you would merge to main and then deploy it to production. When you merge to main, you should release it quickly (with usually a three-day turnaround at most).
Even if it’s a very simple change, after a while, you do get pretty good at creating new feature branches, performing your work, and merging back. This may seem like a crazy three-step process for what might be a one-line change, but it helps you isolate that change and test it in isolation. Following these steps means you don’t have to worry about how it could potentially negatively affect things. I know I’ve been guilty of this in the past. I’ve said to myself, “It’s just a one-line change. The risk is low. We’ll be fine.” No, it wasn’t always fine. Small changes like that can break production.
Keeping that main branch as clean as possible not only helps keep branches clean, but it also means you always have something close to production on-hand. At any point, if production went down (heaven forbid!), you can deploy that main because it’s the last known good version of code.
Feature Branches
Feature branches are where you perform your work. To work in your feature branch, you fetch and then merge from main to update it. There is no checkout required to create your branch from main. After creation, you may want to periodically pull from main and perform conflict resolution in your feature branch if necessary – depending on the changes that have been made.
This is the only merge operation that occurs locally. Often, when you merge to a monitored branch to build a release, you do it on a server-side operation (with a pull request). This merging is usually done in Azure DevOps instead of manually in the client tool.
Merging and Relationships
Don’t be afraid to merge main (and only main) into your feature branch to keep it up to date. You don’t want to merge feature branch to feature branch because you can pollute your branch and create dependencies on both features that could cause problems.
Develop Features in Isolation
Isolate your changes when performing work on the feature branch. Don’t let anybody else’s features that are being worked on pollute your branch. That will be resolved when you merge changes to main.
Finally, before you merge your feature branch to any other branch, ensure that your feature branch builds successfully so when you merge to the main branch it doesn’t cause a failed build. We manage this in Visual Studio, but there are many other tools you can use to manage your Git repository like Git Extensions, Source Tree, VS Code, Command Line, etc.
Benefits Summary
This was a high-level review of the benefits of working with Git, including eliminating deployment dependencies, allowing larger development teams to independently develop without conflicting with each other, managing deployments, and helping prepare for DevOps.





