Using a dimensional data model, especially when scaling enterprise data models and data sets in Power BI, can be exceptionally important to maximize performance from your data.
Rather than doing a deep dive on every single concept of star schema and dimensional modeling, this blog will cover these concepts at a high level – including core concepts, the advantages of using these models in your Power BI datasets, and some additional tools that can optimize your dataset performance.
Core Concepts of a Dimensional Data Model
We’ll start with the core concepts of a dimensional data model and then dive into how that ties into the VertiPaq engine that’s used in the background of Power BI to load your data.
Star Schema
Below we have a snapshot of a sample data model. The tables highlighted in red are dimension type tables. All the attributes that you can use to describe or slice and dice your transactional/fact table data should go in dimension tables. The sales table in the middle with the blue outline is the fact table.
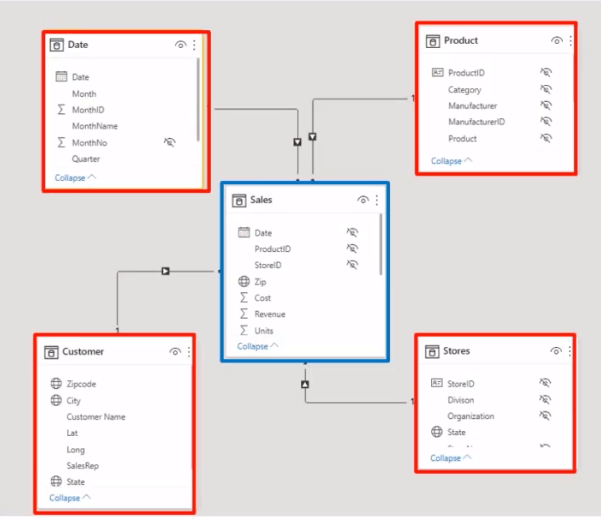
The only fields that a fact or transaction table should have are the fields that you use to create your measures or expressions. In the example above, you see cost, revenue, and units. Those are the fields we will create measures off of. The other fields will be used as relationship fields to your dimension tables and hidden in your dataset.
Relationship fields connect your dimension or attribute tables to those fact tables in your dimensional data model. Again, in the image above, you see those connections. The date in the upper left corner connects to Date in the fact table. Product ID from the Product Dimension also connects. The same can be said about Store ID from Stores and Zip – from Zipcode on the Customer table.
One-to-Many Relationships
We don’t want to have duplicate records in dimension tables, so it’s important that your tables are unique by the primary key field (or the fields or field that make up the unique values in that table). You should aim to create a one-to-many relationships from your dimension to fact tables.
You also want to avoid bi-directional (many-to-many) relationships.
That happens when you have multiple records in a dimension type table for a field being used in a relationship.
In the dimension tables, you should have one unique value for whatever is the primary key or the unique identifier of that table. That creates the one-to-many relationship to your fact table, where you have many values for that Product ID or Store ID or Zipcode.
In the above data model example, you can see how all the arrows are pointing back to the sales fact table. This signals that one-to-many type relationships are being used. In Power BI, if you get a bi-directional relationship, you’ll have a double arrow pointed at each of the tables in your relationship. Though there are situations where bi-directional relationships are necessary, you want to avoid them if possible.
Unintended consequences of using bi-directional relationships in your data model are described in this article by SQL BI.
Using row level security (RLS) in your data model is a situation when a bi-directional relationship is needed. However, the majority of the time you want to stick to one-to-many relationships in the star schema dimensional data model.
Continuous Date Table
The last core concept we want to touch on is making sure you have some type of date table in your data model. That date table should have a continuous date range. A date table with a continuous date range allows you to use the DAX time intelligence measures.
There is a specific button in your Power BI desktop file that says, “Mark as date table.” By marking a date table, you enable the use of DAX time intelligence measures. Time intelligence measures are a very common business requirement in building out Power BI reports.
You will likely use some type of time intelligence calculation in most of your reporting situations. Examples of common time intelligence calculations, include “year to date”, “month to date”, “quarter to date”, “year over year variance”, “month over month variance”, “previous period”, etc.
Why Use a Dimensional Data Model?
Now that we’ve covered some of the core concepts of dimensional data modeling and a star schema, let’s look at why it’s important to follow that structure. You get performance, usability, and model simplicity benefits.
Performance
With a dimensional data model, you are able reduce the size of your dataset by taking advantage of the VertiPaq engine that compresses and loads your data into Power BI. You are also able to return those analytical queries much faster than you would with a normalized dataset.
To explore that first performance point more, we need to look “under the hood” at the Power BI engine: the VertiPaq engine. This engine works very similar to columnstore indexing that you can do in T-SQL. This significantly reduces the size of the data in your model and allows for faster response times in your analytical queries. Since the use case in Power BI is for reporting and analytics, being able to return the data in that format is key (and it’s also why the engine of Power BI is so successful when used with a star schema data model).
The images below show an example of how the VertiPaq engine and Power BI compresses your data. In this first one, you have two columns: color and color ID – which is the unique identifier field in this table example. You have nine rows of color data, but the Power BI engine reads it as the four unique values on the right-hand side.

In this second image (below), it counts the number of rows with that unique identifier. Instead of storing nine rows of data, it stores a two column with four rows, and it counts how many times that unique combination happens in your dataset.
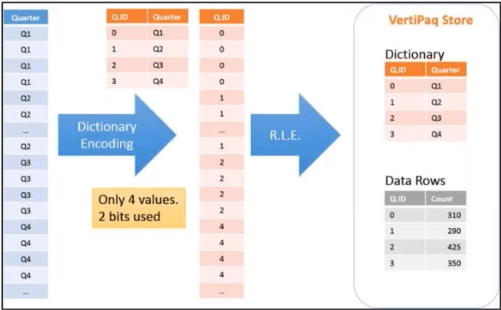
As you can see, it’s important to use dimension tables in your data model to break out the unique attributes you are using to slice your data. Using a dimensional data is much more efficient in Power BI than one large or multiple normalized tables where Power BI is unable to compress that data. That data compression into a columnstore format not only reduces the size of your data, but it allows for much faster query times in your DAX calculations.
Usability
Dimensional data models also offer advantages when it comes to usability. It’s much easier when attributes are broken out into different tables. This also allows for those tables to be reused throughout other data models.
Using normalized tables often hinders reuse of this data. Often a new or altered query is needed for each new business requirement that you are building a report out for in Power BI.
If your source data is already dimensionally modeled, then you can simply pull in the different dimensions or facts that are relevant to the business requirements you are answering with your Power BI report. You don’t have to spend a lot of time rewriting a source query or other queries to bring that data in.
Model Simplicity
That ties into the last major advantage of the dimensional model: model simplicity. By having all those different dimensions broken out you can easily decipher what is being used in that data model and how it all ties together. If we have one, or multiple large normalized tables, that can make it difficult to organize the columns in your dataset. It can also make it difficult to know which columns to use in your Power BI report.
How Do You Performance-Tune Your Power BI Dataset?
Lucky for us, there are four free tools that are directly built off that VertiPaq engine and allow you to use it to its fullest capacity with your Power BI datasets. They are:
- Tabular Editor
- DAX Studio
- VertiPaq Analyzer
- Performance Analyzer
The first three are from SQL BI. With these free tools you can easily analyze your model and find bottlenecks. You could potentially reduce your model size or improve your DAX calculations if they’re not returning fast enough.
Tabular Editor, Dax Studio, and VertiPaq Analyzer can be built into the external tools menu within Power BI. That will link your model directly to those tools. The last one, Performance Analyzer, is built right into the Power BI tool.
Using these tools can help identify if your dataset is in a format to optimize the Power BI’s VertiPaq engine and troubleshoot performance issues with your dataset measures.
Conclusion
This blog covered a lot of information about dimensional data modeling and its advantages. Additionally, if you are looking for help in optimizing your data sets and streamlining your data model, feel free to contact us. We would be happy to help you get the most out of your Power BI investment.




