
When business leaders find themselves interested in machine learning (ML), there is often a desire to jump right into the deep end. But that’s a recipe for failure because a strong data foundation is essential to achieving the desired results of a ML program.
This foundation starts with asking “Why?” To succeed with ML, business leaders must first understand what they want to achieve. Once that is established, there are three essential steps to developing a foundation:
- Source and ingest: Identify a source of data that is external, internal, or a combination of both that you want to analyze.
- Store and transform: Establish the proper system to store and prepare data so it’s easy to access when you need it.
- Model and analyze: Work with internal professionals and external consultants to ensure that the ML foundation you are establishing is set up properly to achieve the goals you want.
Machine Learning Isn’t Magic
Machine learning is one of those buzzwords that captures the imagination. Like Artificial Intelligence and Virtual Reality, ML can become so intoxicating that organizations will often ask us to do it but don’t know why they want it. It becomes an end in itself because it seems to promise prosperity and ease.
But ML is not a magic wand to make competitive insights appear out of thin air. There’s no “easy” button to press and there’s no way to replace teams of people with a click of a button. It’s a tool that requires a strong data foundation. The foundation is key.
There Isn’t an “Easy” Button?
Many ask if machine learning is easy because the tools we use make it look simple, but it’s really about the math. Machine learning is just a set of algorithms. It’s running formulas much faster and more accurately than we can. But it’s still math and completely dependent on the inputs (the data we provide) to do those calculations.
Another common misconception of machine learning is that it’ll just tell you what you need to know. Machine learning isn’t psychic. It’s a tool for deep analysis that will help you answer a very specific question you’ve given it – along with plenty of data.
The Pathway to Data Transformation
As Yogi Berra once said, “If you don’t know where you’re going, you’ll end up someplace else.” To succeed at machine learning, you need more than a lot of data and math expertise. You need to have a plan and think of the bigger picture. The best way to do this is by focusing on the business.
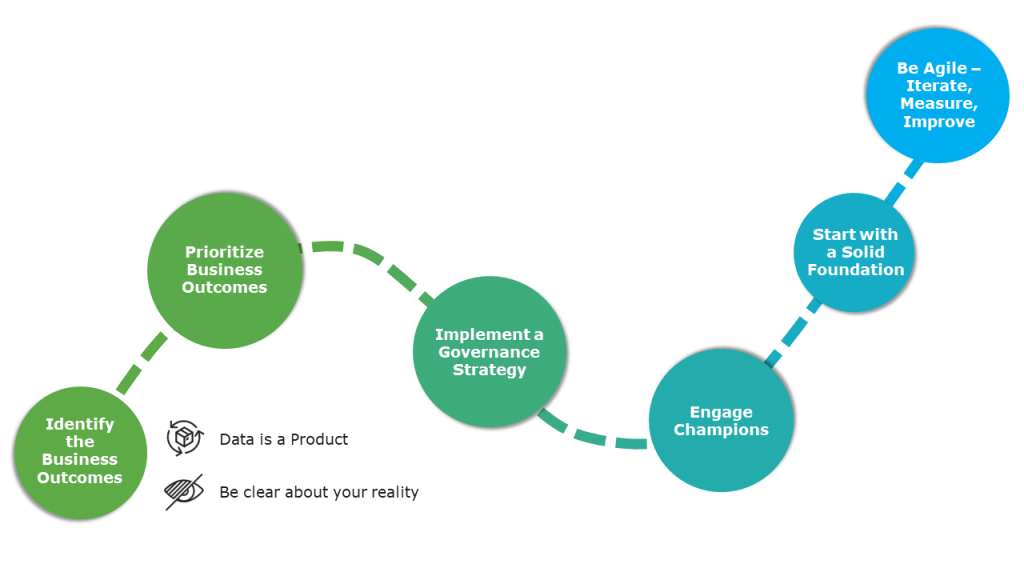
With your business in mind, the journey to machine learning has six key stages:
- Identify the Business Outcomes
- Prioritize Business Outcomes
- Implement a Governance Strategy
- Engage Champions
- Start with a Solid Foundation
- Be Agile: Iterate, Measure, and Improve
1. Identify Business Outcomes
The journey always has to start with the “Why”:
- What am I wanting to drive towards as a business?
- What are my goals?
- What am I looking for?
- Am I trying to increase efficiency and reduce costs?
First identify your desired business outcomes, your goals, and your long-range objectives. We’ve talked with so many organizations who start their journey by listing the data tools they want, but they don’t know why they want them or how the tools will help their business.
2. Prioritize Business Outcomes
Once you have listed your desired business outcomes, prioritize them. Which outcomes are more important than others?
3. Implement a Governance Strategy
After you prioritize outcomes – and before you build anything – implement a governance strategy to properly handle your data. This means setting standards that govern how data is gathered, stored, processed, secured, and disposed of.
Read our eBook: Power BI Governance Primer
4. Engage Champions
Then you need to start engaging your champions. Executive and organizational buy-in are critical. Success hinges on simultaneous ground level support and vision-casting from leadership. Overwhelmed? It’s key to think of this as a program. You don’t have to have all the answers up front, but you should start your data journey with the mindset that it will take time and work.
5. Start with a Solid Foundation
But to be able to do that, you have to lay a solid foundation. Once you have the question you’re trying to answer and have the business champions involved, then you can start with some assumptions. Ask your business subject matter experts (SMEs) why they think a certain situation (like customer churn) is happening. Their responses will be your input into how you build a data foundation that supports analysis into that question.
6. Be Agile – Iterate, Measure, Improve
And finally, the last step in the journey to machine learning is to not tackle all the questions at once. Take one, run it through to get the answers you need, and then move onto the next question.
A Solid Foundation

Having a solid foundation is so important that we’re going to explore it in more detail. A solid data foundation is laid in three steps:
- Sourcing and ingesting: Identify sources of data inside and outside of your organization. Once identified, ingest the data into a solution while aligning integration activities with business goals.
- Storing and transforming: First, tailor-build your data repository. Then transform your data using industry-leading technology, ensuring it’s properly stored and enabled for future analytics and reporting needs.
- Modeling and analyzing: Model your data to ensure consistency and quality. Then make your data accessible and actionable for decision makers by creating dashboards and reports – as well as enabling a platform for moving towards predictive and prescriptive analytics.
Step 1: Source and Ingest
Sourcing data means bringing in the organizational data you need to answer a specific question. You may already be doing this with systems like CRM and ERP; you may have a data warehouse; and you may be using analysis tools like Power BI. Since the data you’re sourcing is being used to answer a question, it’s essential that the data be relevant to the question being asked.
For example, if you want to use machine learning to forecast sales, then you have to start with an assumption that can be measured. If your SMEs assume that certain market factors impact your sales, then that data needs to exist. If the data isn’t in your databases, then you need to get it from public or paid sources. But sometimes the cost of sourcing data outweighs the benefits. Therefore, it’s important to consider the sources and how easily you can acquire them.
Once you have identified your data sources, you need to consider how to export the data you need. There can be a variety of file formats, and you have to be able to support them. Some APIs may let you pull the data from the cloud into your environment. But if the data is in a SaaS system, its format may be challenging to use. This step is called extracting and is part of ETL: extract, transform, load.
You also need to consider how easily you can pull out the pieces of information you need and how the data needs to be structured (or transformed) so you can analyze the information you’re interested in. These questions will come into play even more as you move into the store and transform stage of your journey.
Too many people assume data scientists are needed at this stage, but this foundational ETL work can be performed by a data engineer who knows how to use tools like Azure Data Factory that makes consuming these various sources easier.
Are ETL tools important?
Though tools like Azure Data Factory make it easier, the tool isn’t as important as thinking about the data you need and being able to bring it into a place that you can work with it. Unless you’re getting into big data with high volumes and a wide variety of data, the scalability of most cloud-based solutions can handle your data needs.
Don’t I need big data to do machine learning?
Many people assume they need billions of rows of data to do machine learning. The truth is that, when you are training models and testing them for accuracy, the more data you have, the better. But big data isn’t a prerequisite for doing it; it just provides more data to work with.
Step 2: Store and Transform
For machine learning, instead of using a relational database, we will use a Data Lake because it allows for cost-effective and flexible file storage. The data lake can also be used for end user analytics so you won’t need two separate environments for machine learning and end user analytics.
How do we organize that data when we store it?
We recommend approaching this in terms of different layers. The initial layer might be raw – we land the files the way we get them (ex. if we’re getting JSON files, we’ll save the JSON file). That way, we can always go back and look at it exactly the way we received it. Next, we go through additional layers of curation.
Regardless of how many layers you have and their specifics, try to take data from specific source systems and think in terms of business entities and their relationships. Thinking this way frees data scientist and analysts from needing a detailed understanding of all the source systems.
To structure the data into business entities, consider using something like the Kimball dimensional model; its facts and dimensions lets you easily aggregate, slice, and dice data. It’s helpful to have a framework to organize your data and have a clear pattern of how your data is organized. Otherwise, you’ll end up with a data swamp, and no one wants that.
What do we mean by transforming the data?
It can vary. Imagine you have two systems and they both have a customer. To get insights into the customer, you need to know what records belong to them. Therefore, you have to conform the records in both systems to identify the same customer.
If you’re using Power BI, it might say some of these values are outliers (anomalies). In a normal end user analytics, it may be fine to let that be – meaning the data is what it is. But in machine learning, it can be very important to exclude some of those outliers.
For example, if normally your percentages are being stored as 0.0700% and somebody accidentally put in 7.0, that’s going to get interpreted as 700%. Something like that could throw everything off so you have to cleanse the data.
What does this have to do with machine learning?
All these terms may sound like we’re still talking about data warehouses – and not machine learning – but they’re essential for getting there. So far, the concepts we’ve covered apply to end user analytics – meaning if you want to analyze your data, these are good steps to take in any kind of curated data warehouse data source. However, it’s important to think about the types of additional features you might want to augment your data.
For example, in normal end user analytics, if you want to analyze sales by customer, you might simply analyze historical sales by month and year. But there might be some different ways to think about that data that makes it easier for machine learning to detect patterns. Imagine that your best predictor of customer retention is their first year spend. So how much did they spend in their first year as a client? Looking at their sales over time, you may not be able to easily draw out a pattern. But you can help machine learning easily identify patterns by defining some additional features like their first-year sales, their second-year sales, etc.
How much data augmentation is necessary to successfully set up the machine learning model?
This is where you need to start with your business SMEs because they might have an assumption like, “I think customers quickly drop off after their first year” and they may not know why. Maybe you’re offering incentives the first year, and when the incentives stop, the customers drop off. Your model can’t know that unless you’re giving it that data. To accurately investigate assumptions, you have to define a feature that lets you measure it, and then you can run that through the model.
It is extremely beneficial to work early and often with the human side of machine learning and frequently ask questions like:
- What are our assumptions?
- How can we get that data?
- How can we measure that data?
The answers to those questions should drive your features.
In summary, you need to understand where your data is going to come from, decide how to ingest it, plan where you’re going to put it, how you’re going to organize it, and how you’re going to transform it.
The third step is you need to model and analyze it.
Step 3: Model and Analyze
Having a dimensional model applies to machine learning because defining data to aggregate and creating clear filters for slicing and dicing makes it useful for both end user analytics and for machine learning.
Conforming still applies (to ensure you’re talking about a customer as a customer), as well as having the data be related. You need to see how different data points relate to each other. For example, if you want to see how different incentives relate to sales or client retention, then you need a data model that relates those pieces of data together. Relationships between data are key to enable machine learning.
If you find your insights aren’t helpful, then you need to simplify the model. For example, if you’re doing an end user report, then you may want the option of pulling in the abbreviated or full name version of their home state. However, from an insights or machine learning perspective, you don’t need to distinguish between those. So, in that case, remove one of the state options and that’s enough to see if there’s a correlation between state and something else.
Who can do this work?
If you’re asking yourself who in your organization can do these things, take heart; you don’t need data scientists for creating your data framework. Instead, a data engineer can source and ingest, store and transform, and model and analyze. However, we do recommend that the data engineer get input from a data scientist on those three steps – as well as involving them in the process of answering those vital questions of “What features do we need?” and “What are the assumptions we’re trying to investigate?”
Iterate
If, after testing your assumptions, you find they’re not good predictors, then revisit your initial questions and assumptions. Consult with business leaders and data scientists to uncover any other discoveries that will help you iterate your process. Just like following the scientific method, you should question, hypothesize, test, and validate any and all assumptions.
Analyze
Once you’ve sourced all the data, ingested it, stored it, transformed it, and modeled it to identify relationships, then it’s time for analysis. Whether a data engineer or data scientist is analyzing the data, they should be working with the business to ensure they have business understanding to determine correlation vs causation. There can be coincidences. Involving someone with business context is imperative to filtering out misleading conclusions.
How Do I Get to Machine Learning?
If you’ve been able to get the business and the SMEs, data scientists, and data engineers to work together throughout the process, then you’re on the road to machine learning. However, if you can’t see any connections between your data and don’t know how to identify the relationships, then machine learning won’t be able to do it for you. Machine learning isn’t magic; it won’t be able to understand something at scale if the information doesn’t exist. In summary, there are three keys to success:
Key #1: Know the question you’re trying to answer
If you don’t know the questions, you’re just going to aimlessly wander. The questions you ask should address transformational change like increasing revenue, lowering expenses, reducing risk, etc. You also need to set a specific target so you have something to aim for and achieve. Then you need to ensure you involve your business SMEs in forming assumptions based on those questions and targets so you know where to focus. Starting with the business is absolutely the first step, and you must ensure that the business owners stay engaged through the process.
Key #2: Establish a Foundation
You need to lay a solid data foundation that brings in the data you need and organize it in a consistent pattern. You want to enable the process by putting the data in a clear, consistent format that lends itself to machine learning formulas.
Key #3: Do the analysis and refine
After you formulated your questions and gathered your data, the fun begins. That’s when you can do machine learning. You can start building models on your data, training the models, and running test scenarios. That’s when you’ll reap the rewards of all the work that went into laying your data foundation.
Need help creating a strong data foundation? Contact us today. Our data experts will be happy to help you get to machine learning.






Share on