To deliver projects on-time, on-spec, and on-budget for our clients, our Strategic Services team employs several agile-based methodologies – including user story splitting. Learn more about our approach.
In this guide, we will discuss a common challenge in the world of agile: refining backlog items at the appropriate level of granularity to support completion within a single sprint. This is not always possible but should be one of the goals of backlog refinement.
We begin defining a backlog with higher level stories, breaking them down through elicitation, requirements, and other refinement elements to reach just the right level of detail and effort for a story to be introduced into a sprint. We often have to perform story splitting for solution capability to reach the right level of effort to accomplish this.
Story splitting is one of the most deceptively difficult skills to master in agile. It sounds so easy, “Let’s just a break a big story part into smaller pieces.” But as easy as it sounds, it can be a struggle when first transitioning to agile.
To help you navigate this guide, click on any topic below to be directed to that section:
- What Is a User Story?
- How Do I Write a User Story?
- Alternative Ways to Represent a User Story
- Who Writes the User Stories?
- When Are User Stories Written?
- Horizontal vs. Vertical Slicing
- Why Split User Stories?
- MVP (Minimal Viable Product) to Enhanced
- Spikes & Simple to Complex
- Happy Path and Alternate Paths
- Operations (CRUD)
- Non-Functional Requirements
- Manual vs Automated
- Dummy Data then Real Data
- Device, Platform, and Channel
- Simplest Possible Solution vs Complicated (But Better) Solution
- Conclusion
What is a User Story?
A User Story is a desired capability of a system, written from the perspective of a user, which is valuable to that user. The structure of the story language enforces this perspective of “user driven” thought or need.
How Do I Write a User Story?
There is a typical format that most agile teams use, but this is not prescriptive. Following is the most common method:
As a <some type of user>
I need <something>
So that <I can achieve some goal or benefit>
Some approaches use the term “want” in place of “need.” However, using the word “need” has a psychological impact of setting the expectation that we build what is needed, which is not always what is wanted. A good Business Analyst / Consultant, internal or external, will help the business drive out the difference.
Sample Story:
As a claims representative
I need to view a claim
So that I can evaluate claim for coverage consideration
Although this seems straight forward, it is deceptively simple.
Alternative Ways to Represent a User Story
While the above format is common, one should also express stories at higher levels using Epics, then Features, under which will reside the User Story.
Often, the initial discussion around capability is high level. This results in vague definitions of need. For example, in an Insurance organization, processing claims is a central capability. Often, users will explain things simply to the Business Analyst, such as “we manage claims.” However, “manage claims” is quite vague and there are likely multiple capabilities or outcomes associated with that high level definition. This is indicative of a need for a high-level story that should lead to more granular User Stories. “Manage Claims” is such a high-level need that it should be an Epic. Epics would represent large levels of capability a solution should offer and should be written in verb noun format like “Manage Claims”.
Epics can be further decomposed into Features that enable the need defined in the Epic, such as:
- Search Claims
- View Claim
- Manage Claim
- Evaluate Fraud
- Perform Underwriting
Within Features, you will find Backlog Items or User Stories. These should be at the lowest level appropriate for a reasonable effort for implementation. The goal is to create backlog items or stories that can be complete (including testing etc.) within a single sprint.
User Stories are not intended to be tasks or tactical activities to be executed on. Those are handled via the task breakdown when a “ready” story is pulled into a sprint during Sprint Planning.
Acceptance Criteria is essential to a complete User Story. This is when refinement activities result in more detailed understanding of the needs associated with the story for business value to be realized. This can take many forms and will vary based on the specifics of the User Story.
Who Writes the User Stories?
Ideally, stories are written by the Business Analyst in collaboration with the Product Owner and reviewed and verified by Development Team members. Anyone can contribute, but that does not necessarily mean that every story will be prioritized by the Product Owner to be developed. Ideally a Business Analyst is facilitating these activities to ensure the most objective and complete / ready User Stories.
When Are User Stories Written?
User Stories are ideally ready approximately two sprints in advance. This is often referred to as “just in time.” You want to be a bit ahead to ensure there is a good understanding of what needs to be developed (which enables effective expectation setting and accurate estimation of effort) so the sprint is at that goldilocks (not too much, not too little…just right) spot of full.
If the stories are prepared too far ahead of the implementation team, things are likely to change. If you have a product skeleton built, with the high-level Epics and Features, that will provide you with a good framework for deciding when to break items into smaller chunks (User Stories) that can be completed within a Sprint.
Horizontal vs. Vertical Slicing
Defining stories at the right level of granularity and effort can initially take trial and error. Large stories ideally decompose into smaller bite-size chunks that can be completed within a sprint. Teams also struggle with the concept of “slicing the cake” or taking a vertical cut through all the technical layers. Understanding this concept is of key importance before discussing splitting stories into manageable pieces.
What Does It Mean to “Slice the Cake”?
“Slicing the cake” means to take a vertical slice through multiple architectural layers, rather than fully building each horizontal layer in sequence.
In the following illustration, one can see how a vertical slice cuts through all the technical layers, but it is a minimum set of capability that grows over time, delivered incrementally. Instead of waiting until all horizontal layers are built, deliver a subset of working software that has value to the users sooner. They may not have everything all at once, but they have enough that they can test it out and give feedback.
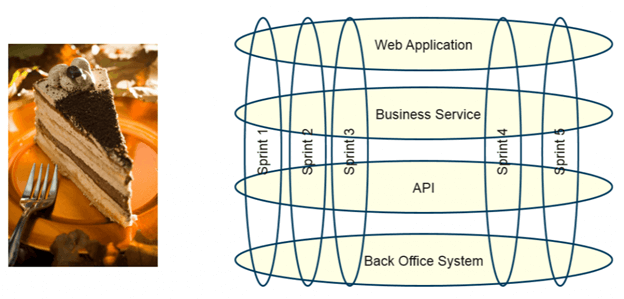
This can be difficult, and it is easy to fall back into old habits where teams revert to building out the horizontal layers – even going as far as to write so-called “technical stories” or tasks for each horizontal layer. This is not the best approach in agile and should be avoided.
Stories should be written from the customer or end-user perspective, including the “who,” “what,” and “why” to ensure they deliver business value. By slicing stories vertically, one ensures delivering on that promise to provide smaller pieces of value, sooner.
Why Split User Stories?
Splitting stories allows for smaller amounts of capability that can be completed within a single Sprint. Things that can contribute to complexity resulting in a need to split can be:
- Too many steps
- Difficult quality assurance elements
- Lack of sufficient clarity on need or complexity
- Eliminating previously built capability
The goal is to reach minimal marketable feature (MMF) or minimal viable product (MVP) as soon as possible. This allows release to market and start getting feedback. If there are things that can be deferred until later (or never), the highest value functions can be delivered earlier, and the team can learn from those elements to ensure the overall highest quality and value-focused solution. This should be done in a way where the team has a strategic roadmap. Although the minimal elements are built first, they should be built in such a way as to afford scalability and extensibility. It is ideal to build today with tomorrow in mind.
Splitting or re-combining stories can occur during Sprint Planning. This is an art more than a science, and eventually the best splitting methods for the team will surface.
Practice, Practice, Practice
The more this is practiced, the more natural and intuitive story splitting will become. This is not something that is accomplished with expertise in a day. It takes time and collaboration within the team to find that “goldilocks” spot of story splitting.
Now we will dive into various splitting scenarios and how to best do so with excellence.
MVP (Minimal Viable Product) to Enhanced
Vertical slicing leads us to MVP (Minimal Viable Product). MVP refers to “must have” capability levels necessary for a usable product to be released. This affords an opportunity to ensure the solution can truly provide value and, if appropriate, be adjusted to ensure needs are effectively met in the value delivery.
Once the MVP has been released, the team can iterate to provide further enhancements until the team feels like they have reached the point of diminishing returns. This provides an opportunity to enhance time to market.
A good example often used in agile training is the Agile Bicycle. However, that analogy is flawed. There is a blog that addresses the flaws of the original analogy. In the revised analogy, the User Story might go something like this:
As a person,
I want to get from point A to point B using my human energy, but without walking or running,
So I can get to where I want to go faster
What might be the absolutely must-have Features of this device?
- Two wheels
- A way to connect the two wheels
- Something to sit on between the two wheels
In this first pass, the product would be very crude, but it could be used to propel a person forward in a straight line using the power of the legs, but with much less expenditure of energy. This would represent the MVP.
Future iterations would then enhance the original MVP, using feedback from users to drive additional User Stories in the Product Backlog.
A second iteration might include these additional Features:
- A method to steer or change the direction of the front wheel so you can travel in curves, not just a straight line
- Something to rest your arms on
- A way to keep the device upright when not in motion
This makes for a slightly better bike.
A third iteration could add these Features:
- A handlebar rather than an armrest
- A way to propel the bike without putting your feet on the ground (pedals)
And so forth…
Once the basics are provided, further enhancements can be made such as:
- A solar-powered human-machine interface (HMI, aka: a computer screen on the dash)
- A lock built into the bike
- Ability to lock and / or unlock the bike using the HMI with a password, an RFID card, or a mobile phone
- Voice- and screen-guided biking directions using bike paths
- GPS trip tracking (map of your biking route)
- Distance, time, and calorie calculations
- Warnings if the bike needs maintenance
As you can see, the bike has come a long way from the original MVP. This is a fantastic way to start with a large vague idea, pare it down to its most basic Features, and then incrementally and iteratively enhance the original version to build a better product.
Questions to ask:
- What are the essential Features needed to accomplish the user’s goal?
- What could be deferred until later?
- How important is it to be first to market or gather feedback quickly?
Spikes & Simple to Complex
Spikes
Spikes, or Research stories, may happen when there is not enough information to move forward, and research or investigation is necessary to enable development or implementation work.
A spike would deviate a bit from a traditional User Story format like “Investigate options for including charts on mobile devices.”
Spikes are often more useful when it requires an Implementation SME (Subject Matter Expert) to investigate solution approach options to determine feasibility or effort. Deeper dives into requirements and business / user need are done through refinement. There is not a similar simplistic approach when a technologist needs to allocate time to investigate said feasibility. Therefore, Spikes are treated like a story in all but format and enable the team to allocate technologist time during a sprint to investigate for feasibility or technology approach for the given need. This allows for effective management of velocity, resource availability, and other important tracking metrics.
At the Sprint Review, the results of the research story would be presented to the team, and (hopefully) a decision would be made on how (or whether) to move forward.
Spikes should be used as an exception, not a rule. If this becomes a thing of frequency, investigation would be warranted to determine if requirements are vague, or if the story is too big or complicated.
Simple to Complex
It is best to begin with simple core functionality, which can provide the basis for gathering feedback from users and using that to inform what should be added next. This is remarkably similar to starting with an MVP and then building on it.
As mentioned previously, it is important to segment capability down to a reasonable level. It is ideal that a story is at least two hours, but no more than forty (with a few exceptions). To accomplish this, a single application screen can be broken down into the most basic functionality, and additional capability can be incorporated in a later sprint to extend the solution.
Using our Manage Claims example, one can identify multiple stories for this without preventing usable capability from being delivered as soon as possible. For example, “Manage Claim” can be broken down into the following capabilities:
- Create Claim
- Edit Claim
- Approve Claim
- Reject Claim
- Submit Claim to Fraud
- Submit Claim to Underwriting
Any of these activities leads to a claim conclusion (Approve or Reject). This could be broken down even further:
- Create Claim
- Put claim on Hold
- Obtain missing information
- Edit Claim
- Put claim on Hold
- Correct claim data
- Obtain missing information
- Approve Claim
- Approve Claim < 1000
- Approve Claim > 1000
How simple should simple be? Given our preferred rule of a story requiring at least two hours of development effort (and a manageable testing effort), It would be unlikely to split “create claim” and “edit claim” as they both have almost identical capabilities. This would result in a story that would take only minutes to complete (the difference between a “New” capability and a “Edit” capability only being differentiated by the current state of a record). However, the approval element impacts workflow given that any claim over $1,000 requires management approval. The necessity of workflow increases complexity enough that it calls for its own story.
Therefore, the first story would be Create / Edit claim. This lays the foundation for all other stories that will extend the capability of the Manage Claim screen while providing immediate capability a user can leverage to ensure their needs are met as efficiently and reasonably as possible.
The statuses listed (In Progress, Pending Information, Pending Fraud, Pending Underwriting, Approved, Pending Approval and Rejected) would all be available in the first iteration of the solution. Users would manually search for and manage the claims based on status. In future iterations of the extended solution, an automated workflow would be implemented via multiple additional stories building on the solutions capability while quickly offering near term value.
Questions to Ask:
- What is the absolute simplest version of the solution that would provide usability?
- Are there logical groups of data that can be split out to begin and extended with additional data later?
- What is “enough” to get useful feedback from users?
Happy Path and Alternate Paths
User Stories and Acceptance Criteria should address both the happy and alternate paths of a story. Happy path, or main path as many refer to it, represents the perfect situation where there are few (or no options) and nothing goes wrong. The preferable post condition is reached, and the goal of the User Story can be accomplished where nothing goes wrong. Whereas an Alternate Path includes any alternative (other post conditions) or exception paths (minimum guarantee cannot be completed) that might be possible. (NOTE: this is Use Case terminology)
A great business analysis tool to model or depict the possible paths in a flow is an Activity Diagram (UML) (often used to visually depict the various paths of a use case, which is still highly valuable in Agile). This model resembles the workflow diagram but is agnostic of users and simply follows the flow of activities.
Example of a Happy / Alternate Path
Let us assume that, for managing a claim, users must have an account with the system before they can access claims due to regulatory controls and compliance. The happy path for logging into the system would be that the user already has an account, knows their credentials, enters them correctly, the system authenticates the user, and they can access the system.
An example of an alternate path might be that the user has an account, but they entered their credentials incorrectly and therefore can’t access the system. Here is what this would look like in an activity diagram:
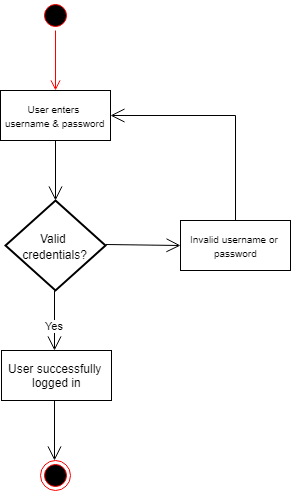
Other examples of alternate paths might be that the user doesn’t have an account yet or wants to recover a forgotten username or password (not included in the diagram above).
You can probably see how these types of diagrams can be useful but can also become complicated in proportion to process complexity, and the number of splits, exceptions, or alternate paths. This is sometimes still necessary for a holistic understanding but indicates that capability should be split into multiple stories.
In Use Case reference, a single Use Case ties together multiple User Stories with an experiential understanding. Therefore, Use Cases are valuable to the team to increase understanding of what the user should experience overall and can then be split into multiple stories to incrementally accomplish that holistic experience.
Following is an example of a Login experience and how it breaks down into multiple User Stories:

Start with the happy path when breaking down User Stories:

Then an alternative path story would be:

Often, more alternative paths will exist, and the splitting will continue until all necessary paths have been defined.
Questions to Ask:
- Can the “happy” path be easily split from alternative paths in a flow?
- Are all paths necessary to start with, or can they wait?
- Are there any alternative paths that can be eliminated? (Think exceedingly rare use cases)
Asking these questions will help determine priorities.
Operations (CRUD)
In software development, most Features include the standard operations of “Create,” “Read,” “Update,” and “Delete.” When “Manage” is used to reference behavior, it is a clue that this might be an operational process encompassing the CRUD elements.
Taking us back to the claim example, managing a claim can break down into the following:
Splitting based on CRUD and other operational lines should be reasonable and avoid adding unnecessary overhead with tracking tasks and moving stories across boards. For example, creating, reading (viewing), and editing a claim are almost identical in system capabilities that must be implemented. Therefore, it would not be prudent to split these capabilities into separate stories as you would have two stories (edit and read) that would be negligible on the effort. However, deleting a claim may have a decent amount of effort associated with deletion constraints. This example would make sense to split into a new User Story but must come after the Create / Edit / View User Story.
Based on the above guidelines, the ideal splitting of stories would be:
- Create / Read / Update Claim
- Delete Claim
- Approve Claim
- Reject Claim
- Submit Claim to Underwriting
- Submit Claim to Fraud
Questions to Ask:
- Are all the operations absolutely necessary?
- Does it make logical sense to combine any of the operations, such as Create / Read / Update?
Non-Functional Requirements
According to the BABoK (International Institute of Business Analysis’s Business Analysis Body of Knowledge) Non-Functional Requirements are:
“A type of requirement that describes the performance or quality attributes a solution must meet. Non-functional requirements are usually measurable and function as constraints on the design of a solution as a whole.”
A little trick IIBA BAs use is if the word ends in “ility”, then it’s probably a non-functional requirement (not a rule). Here are some examples:
- Availability
- Usability
- Extensibility
- Reliability
- Scalability
- Compatibility
- Security
- Efficiency
The list of possible non-functional requirements to consider could be endless. But these are requirements that can increase risk if they are not considered. Agile can introduce complexity with managing nonfunctional requirements, but the following are some ways that can be considered to accommodate it (when the nonfunctional requirement does not easily fit into an existing path story):
- Include them as part of a definition of done that applies broadly across the whole effort
- Include them as acceptance criteria on individual stories
- Include them as a separate bucket of requirements
- Include them as “Spikes” that are managed separately to prove out architectural strategies
- If complicated enough to justify its own story, a User Story with minimal acceptance criteria is acceptable.
Let us take performance efficiency as an example. At the beginning stages of a project, performance may be of low concern. The environments used for development and testing may not be the most robust, but that is of less concern early in solution development.
The big story would be, “Performance Efficiency”.
Given that inclusion in other stories is managed in other sections, the focus here will be on non-functional requirements as separate User Stories, such as:
As a Claim Representative, I need the application to load within two seconds so that I can meet the required average claim processing time KPIs.
Given that performance concerns are not of great concern early on in projects, these would be included in the product backlog to ensure they are not forgotten or ignored (and educate the Product Owner about their importance).
Non-functional requirements are often the most difficult ones to elicit and to define. This is for several reasons:
- They must be measurable
- They must be testable
- They are not often part of the natural user thinking and are therefore not naturally provided by users; they must be elicited and often require more effort by the Business Analyst to do so
Questions to ask:
- Can the quality attribute wait until a later time?
- Is it something that must eventually be done to have a quality product?
- How can it be measurable so it can be tested?
- Are there areas to reduce quality because it is less important?
Non-functional requirements can dramatically increase the cost of a project. Is focus placed on only the most important ones?
Manual vs Automated
If a process can be managed manually, even temporarily, it can enable teams to quickly provide business value. The automation of the process can be done later. Some examples of manual vs automated follow:
Data
- MVP: Manually updating data is often a much quicker capability to provide. The data points must be created regardless of how they are populated and presentation of said data must still be provided. Therefore, allowing the user to manually maintain the data at first is a quick win.
- Next: Incorporate, if possible, an automation of the data population (document digitization, data feeds from external parties, data feeds from other applications within the organization, etc.). Once this capability is incorporated, the user can still update data if needed, but much of the maintenance of the data is automated, improving both efficiency and data quality.
- The only exception to this is if there is a reasonable concern of data quality or duplication of data if a single source of truth cannot be provided in the beginning.
Workflow
- MVP: Users can manually update status and manually notify other resources in the organization when a record is ready for their portion of a process. While this reduces efficiency, it at least immediately provides the team some capability.
- Next: Certain data values or actions by the user can automatically change the status – driving automated movement into another resource type’s functional area. The system can automatically notify, or a “queue” capability can be provided in later iterations of the solution.
Questions to ask:
- Will a manual process work to start with?
- How often will the manual process need to be performed? (And how long will it take?)
- Will a significant amount of time and / or money savings be achieved by automating the process?
In some cases, it will make sense to do automation right away, but this should be an objective evaluation.
Dummy Data then Real Data
Access to data resources can be effort intensive to enable. If getting real data is complicated, an initial story can assume the team will add data manually (whether accurately reflective of real / live data or not to enable forward progress). While the team is validating functional capability, additional effort can be put into acquiring data from the needed data sources.
Once the needed data is available, integration of said live data can be completed, allowing necessary testing and verification. This allows rapid progress and validation of capability and provides overall efficiency of solution delivery. This would require a secondary story for incorporating the live data.
Questions to ask:
- Is it going to be a while before your real data can be acquired?
- Is there a way to move forward with fake or dummy data to get the function working?
- Is the team confident in the ultimate data structure?
Device, Platform, and Channel
There are countless combinations of devices, platforms, and channels that could be leveraged to provide business agility in solution use. Very often, it is ideal to have a fully functional, robust, and web-based application, but that can become cumbersome for resources that have a decent amount of mobility associated with their function.
In these scenarios, teams will often build the fully functional solution first (following the Now, Next, Later idea) and, once enough capability has been built on that platform, the solution is evaluated for appropriate functions to be provided via a mobile application. Mobile applications often require different things and, often, a different layout or user experience. Typically, mobile applications provide a subset of capability that the full application (often web-based) provides.
Critical evaluation should be done to ensure unnecessary mobile development is not attempted. Very often, mobile platforms have rigorous approval processes. Therefore, the team would want to ensure they maintain awareness of diminishing returns concerns on mobile capability. An exception would be if the codebase used is easily portable across multiple platforms. If the capability of both the full application and mobile implementation are similar enough in codebase, then a single story would be used with acceptance criteria calling out the platforms on which the described capability should be available.
Questions to ask:
- Are any channels / platforms more important than others?
- Is there a mobile-first strategy, or is it more of a traditional approach?
- Must the solution be developed for all channels, or can it be narrowed down to the most used?
- Are there certain aspects of a feature that differ significantly across platforms?
Simplest Possible Solution vs Complicated (But Better) Solution
Often, simplicity and limited capability can provide enough for the solution to meet a need, even if the approach is not ideal. For example, if the solution requires a date data element, the ideal solution would be to have a date picker where the user could quickly select a date that is automatically formatted for them. However, at first, is this necessary? Or could a text box for the user to manually enter the information be sufficient until a later iteration?
Another example is selection lists. Ideally, if the selection list is long, the system would enable type ahead lookup for a selection list value. However, at first, the selection list could be limited to scrolling for item selection.
Another user interface element that can be split is specific to branding. Often, initial solutions can be leveraged internally for validation and preparation. This approach allows a simpler user interface to be developed initially. Before the solution is presented to a larger group or external to the organization, a branding layer can be added. This allows time for the solution to “come to life” with capability and, shortly before full release, a more aesthetic layer which appropriately represents the brand of the organization.
These are just a couple of examples. There are many opportunities to provide simple (but elegant) capability at first that can be augmented with more user-friendly, enabling, or automated capability through continuous improvement.
Questions to Ask:
- Can simplicity suffice near term with complexity coming later?
- Can updates be made at the source, rather than having an aesthetically pleasing interface to make changes?
- Can manual processes be leveraged in the beginning and apply automation later?
By building “just enough” to be able to release and get feedback, the true need becomes much clearer, much sooner.
Conclusion
Agile implementation of value requires stories that are “just right” or “goldilocks” in size to enable delivery of value without extensive time investment. This enables learning earlier in a change initiative – allowing the right value delivered at the right time to avoid significant cost associated with learning too late in a solution’s lifecycle. This requires the learned skill of decomposing of capability to a level of granularity needed based on the elements discussed here. If this skill can be developed or matured in a team, an organization is more poised to accomplish business agility through product or solution development.
If your organization needs to deliver the right value at the right time, contact us today. Our project experts can help.



